Tester la normalité
Une expérience : le dilemme du prisonnier
Le dilemme du prisonnier est une reformulation psychologique proposée par le mathématicien canadien Albert Tucker, de la théorie de la coopération et du conflit proposée par Merrill Flood et Melvin Dresher (Rand Corporation) en 1950.
Le scénario est le suivant : deux criminels ont commis ensemble un délit et sont arrếtés, mais la police ne dispose pas de preuves formelles. Aucun d'entre eux ne veut avouer. On les interroge séparément et on leur fait individuellement la proposition suivante : « si tu avoues, tu t'en sors avec une peine légère (mais ton complice est lourdement condamné). Si tu n'avoues pas, mais que le complice avoue, c'est toi qui prend une lourde peine.»
Il y a deux conséquences à cette proposition : i) si les deux (qui ne peuvent communiquer) avouent, ils vont tous les deux en prison pour longtemps, ii) si les deux choisissent de ne pas avouer, alors ils sortent libres, faute de preuves.
Le dilemme, pour chacun d'entre eux, est de décider s'ils trahissent ou non leur complice. Dans cette situation où ils ne peuvent communiquer, la tentation est grande de trahir, en espérant s'en sortir à peu de frais. Le meilleur choix, celui de ne pas trahir, suppose en effet une confiance sans faille dans son complice, car c'est uniquement s'il choisit lui aussi de ne pas trahir que l'issue est positive pour les deux malfaiteurs.
Cette situation, aussi simple qu'elle paraisse, peut être retrouvée dans de nombreuses situations de la vie politique et économique, ou un choix de collaboration vs. non-collaboration, en l'absence de communication directe possible, doit être fait (voir Eber, 2006, pour une synthèse en français).
Fox & Guyer (1978) ont proposé à 20 sujets, dans une expérience de laboratoire, de prendre 120 décisions de ce type dans une situation dite de « dilemme du prisonnier répété ». Sur les 120 essais, on a compté le nombre de fois où ils ont fait le choix de la non-trahison. Ce comptage fera office, dans les analyses qui suivent, de score de coopération.
Ils ont contrasté deux conditions dans cette expérience : i) une condition dite anonyme, où leur décision n'est pas communiquée au partenaire distant, ii) une condition dite publique, où leur décision est communiquée. Les auteurs cherchent à voir dans quelle mesure le caractère public de la décision peut favoriser le choix de coopérer. Comme variable contrôlée supplémentaire, ils enregistrent aussi le genre des sujets (20 hommes et 20 femmes). On se concentre ici pour l'instant seulement sur l'effet de la condition de décision.
Dans toute analyse statistique en psychologie, il y a deux phases : i) la construction d'un modèle convenablement ajusté aux données, et ii) l'interprétation des paramètres au sein de ce modèle. Clairement, si le modèle est mal ajusté aux données, cela n'a pas de sens d'interpréter ses paramètres, leur taille, et leur éventuelle signification psychologique. Pour traiter cette question sous la forme d'une comparaison de moyennes, nous avons besoin d'abord de valider un modèle de moyennes.
Atelier
On examine dans cet atelier les données de Fox & Guyer (1978) pour tenter de mettre en évidence un effet de la condition (publique ou anonyme) sur le score de coopération.
- Téléchargez le fichier de données guyer0.csv sur votre disque. Pour que le type CSV du fichier soit préservé, évitez de l'ouvrir avec votre tableur : faites un clic droit ("Enregistrer la cible du lien sous...") et non un clic gauche.
- Ouvrez-le dans l'interface R2STATS ci-dessous (onglet Fichiers) et examinez la présentation du tableau des données (onglet Donnnées).
- Dans l'onglet Modèles, cliquez sur le nom des variables tour à tour pour examiner leurs résumés (moyennes, fréquences...) en bas de page.
- Testez un modèle M1 postulant l'impact de la condition sur la coopération. Répondez aux questions du quizz ci-contre à l'aide des résultats obtenus.
-
expand_moreEn résumé
Cet exercice permet de revoir que :
- Dans le tableau des Paramètres, R2STATS représente les deux moyennes de groupe sous la forme : i) d'une moyenne de référence (ici la moyenne du groupe Anonyme) et ii) d'un différentiel, ici du groupe Public au groupe Anonyme.
- Cette manière de faire non seulement représente exactement la même information que les deux moyennes, mais permet de représenter et de tester plus facilement un nombre quelconque de moyennes ordonnées et leurs différences (voir la partie Analyse de la variance).
- Des tests de Student de comparaison à la valeur théorique 0 sont automatiquement calculés pour chaque terme de cette décomposition.
- Le premier de ces tests (pour comparer la moyenne du groupe Anonyme à zéro) n'a pas nécessairement d'intérêt ici, mais selon les contextes cela pourra être le cas (par exemple quand on teste une évolution).
- On est attentif au calcul de la valeur $p$, selon la direction de l'hypothèse alternative. Par défaut, les logiciels statistiques fournissent des valeurs $p$ bilatérales. Il faut donc la diviser par deux si l'alternative est unilatérale, dans un sens ou dans l'autre.
- Le $T$ de Student pour la comparaison de deux groupes indépendant est une statistique de décision s'appuyant sur un modèle affirmant l'homogénéité des variances de scores et la normalité des distributions dans chaque population parente. Le test d'homogénéité des variances a été vu précédemment. C'est l'objet de la partie suivante que d'étudier deux statistiques pour tester spécifiquement l'adéquation satisfaisante d'un modèle de loi normale.
Décomposition d'un score en moyenne et résidu (modèle de score)
Dans cette situation, nous pouvons penser à utiliser un $T$ de Student pour comparer les deux moyennes de coopération dans les conditions publique et anonyme. Mais les résultats d'un $T$ de Student n'ont de sens que si le modèle qui les fonde (le modèle de groupe gaussien) est correctement ajusté aux données. Celui-ci fait en particulier deux hypothèses statistiques fortes sur la structure des données : elles suivent une loi normale dans les populations parentes, de moyennes potentiellement différentes mais de variance identique. Un test approprié pour l'homogénéité des variances a été utilisé ici, et nous étudions dans cette partie le test de Shapiro-Wilk, qui permet de tester spécifiquement l'adéquation d'une loi normale.
Pour situer la place exacte de l'hypothèse de normalité dans le modèle de groupe, nous allons le reformuler en décomposant le score de coopération d'une nouvelle manière.
En numérotant par $j$ ($j=1,...,J$) les conditions comparées, on écrit : $$X_{ij} = \mu_{j}+\epsilon_{ij}$$ en faisant l'hypothèse de distribution que $X_{ij}\sim N(\mu_{j},\sigma^{2})$.
Le score du sujet est ainsi découpé en deux parties : une partie fixe ($\mu_{j}$), qui différencie les groupes par leur moyenne, et une partie aléatoire ($\epsilon_{ij}$), qui caractérise la position individuelle d'un sujet au sein du groupe, en écart à la moyenne de sa condition. Chaque sujet se caractérise par un écart aléatoire à la moyenne du groupe auquel il appartient, et la dispersion globale des scores dans les groupes est supposée de variance homogène $\sigma^{2}$ pour tous les groupes.

Cette décomposition peut être appliquée à toute situation où des conditions expérimentales sont contrastées, que l'on souhaite caractériser chacune par un paramètre global de moyenne. C'est fondamentalement un modèle où l'on se concentre sur les caratéristiques de groupes, et où les individus ne sont représentés que sous la forme d'une hypothèse de distribution sur leur distance à la moyenne. Cette distance à la moyenne n'a pas de structure définie (autre que distributionnelle) et est considérée comme de l'erreur (c'est-à-dire comme résultant de l'impact d'un ensemble de facteurs indépendants du facteur expérimental étudié).
Ce modèle fait sens davantage en expérimentation par exemple, où l'on choisit de considérer que tout sujet placé dans une condition standard verra son comportement impacté de la même manière, à un aléa indépendant près, que l'on considère de variance homogène dans toutes les conditions. En pratique, nous ne connaissons pas les moyennes vraies de condition $\mu_{j}$, mais nous les estimerons sur les données au maximum de vraisemblance par les moyennes empiriques de groupe $\bar{y}_{j}$ (en appliquant toutes les corrections nécessaires suite à ce remplacement).
Comme on peut le voir, le modèle de groupe est donc fondamentalement un modèle de moyennes, qui résume intégralement les propriétés des conditions expérimentales par une valeur centrale unique, structurant fortement la performance de groupe. C'est le modèle qui donne du sens à la notion même de comparaison de moyennes. Pour cette raison, les moyennes dans ce modèle sont considérées comme une prévision faite par le modèle (en espérance) sur la performance réalisée par un sujet, dès lors qu'on sait à quelle condition il appartient.
Par contraste, la variable d'écart $\epsilon_{ij}=X_{ij}-\mu_j$ est appelée variable résiduelle, car elle mesure l'écart entre score réel $x_{ij}$ et prévision $\mu_j$ proposée par le modèle. On note que cette variable résiduelle est attendue de moyenne 0 et de variance $\sigma^2$, pour toute observation dans quelque condition que ce soit : $$\begin{aligned} E(\epsilon_{ij}) = E(X_{ij}-\mu_j) = E(X_{ij})-E(\mu_j) = \mu_j - \mu_j = 0 \\ V(\epsilon_{ij}) = V(X_{ij}-\mu_j) = V(X_{ij})+V(\mu_j) = \sigma^2 + 0 = \sigma^2 \end{aligned} $$
Si nous voulons tester l'hypothèse de normalité, nous pouvons donc nous concentrer sur cette variable des résidus du modèle, car en dépit du fait qu'elle se déduit d'un modèle à plusieurs groupes, elle est caractérisée par une distribution normale de moyenne unique et de variance unique sur les résidus : $$\epsilon_{ij}\sim N(0,\sigma^{2})$$
Normalité des résidus du modèle
Dans l'analyse des données de Guyer & Fox (1978), on peut examiner les résidus du modèle en calculant pour chaque sujet les différences entre leur score réel et la valeur prévue par le modèle (moyenne de leur groupe). Les données, valeurs prévues et résidus observés, sont rapportés dans le tableau ci-dessous.
Le sujet 1 dans le groupe 1, par exemple, a obtenu un score de coopération de $x_{11}=49$, et selon le modèle de groupe nous prévoyons pour tous les sujets en condition publique un score unique $\bar{x}_{1}=55.7$. Le résidu du modèle pour cette observation est donc $e_{11}=49-55.7=-6.7$. Cette valeur mesure l'erreur commise par le modèle de groupe dans le compte-rendu de la performance du sujet 1 du groupe 1. En faisant ce calcul pour toutes les observations, on obtient ainsi les valeurs indiquées dans la colonne Résidus. Nous examinons dans cet atelier comment se distribue la variable Résidus, et cherchons à mesurer un éventuel écart à la loi normale.
Atelier
Préparation des résidus
- Cliquez sur le bouton de téléchargement ci-dessous pour ouvrir le fichier dans un tableur (nous allons faire un peu de calcul).
- Faites un tri croissant sur la colonne des Résidus. La valeur minimale est -26.7 et la valeur maximale est 23.3. Pour nous simplifier la tâche, nous allons standardiser cette variable résiduelle. Cela nous permettra de comparer sa distribution à une loi normale standard (car il existe une infinité de lois normales possibles).
-
Calculez en bas de colonne la moyenne des résidus en saisissant la formule : =MOYENNE(E2:E21).
Une propriété de la somme des écarts à une moyenne est qu'elle est toujours nulle (voir Manuel de cours, p. 14) : la moyenne des résidus est donc toujours nulle. - Calculez en bas de la même colonne la variance corrigée des résidus : la somme des carrés doit être divisée ici par $N-2=18$ car nous avons deux moyennes estimées : =SOMME.CARRES(E2:E21)/18.
- Créez en F une colonne "Résidus standards" et mettez-y les valeurs de la colonne E précédente, dont vous soustrayez la moyenne et que vous divisez par la racine de la variance commune (utilisez la fonction RACINE() du tableur, sur la case qui contient la variance).
Une fois préparés les résidus, nous spécifions maintenant leur distribution. Le principe de plusieurs tests de normalité (Kolmogorov-Smirnov, Shapiro-Wilk) est de spécifier cette distribution sous une forme cumulée à gauche, en calculant la fréquence des observations qui sont inférieures à une certaine valeur (ou coupure inter-valeurs).
Caractérisation de la distribution
- Créez en G une colonne d'effectifs cumulés à gauche, nommée E.C., qui indique combien pour chaque résidu on trouve, dans la série ordonnée, de valeurs inférieures ou égales à lui. A l'évidence, il n'y a qu'une valeur égale ou inférieure à -26.7 dans la série ordonnée des résidus : c'est -26.7 elle-même. Procédez de même pour les autres valeurs.
- Créez en H une colonne supplémentaire de fréquences cumulées à gauche, en divisant simplement les effectifs cumulés précédents par le total de sujets ($N=20$). Petite subtilité : nous calculerons cette fréquence cumulée en introduisant une correction dite "de continuité", en soustrayant d'abord 0.5 à chaque effectif. Par exemple, pour la première ligne, la fréquence cumulée corrigée est obtenue par la formule : =(G2-0,5)/20.
Caractérisation de la loi normale la plus proche
Nous cherchons maintenant à examiner comment cette distribution cumulée est suffisamment proche d'une loi normale pour qu'on accepte cette approximation. Il existe deux approches pour cela :
- une approche (Shapiro-Wilk) qui calcule les résidus théoriques que l'on devrait observer dans la loi normale pour les mêmes valeurs de cumul que nos fréquences observées. Ces résidus théoriques sont ensuite comparés aux résidus que nous observons, par un graphique de corrélation.
- une approche (Kolmogorov-Smirnov) qui calcule les probabilités cumulées de la loi normale standard pour les mêmes quantiles standardisés que nos résidus. Ces probabilités cumulées normales sont ensuite directement comparées aux fréquences cumulées que nous observons, par un calcul de distance.
- Calculez dans la colonne I les valeurs de variables (quantiles) de la loi normale standard associées aux fréquences cumulées qui sont en colonne H. Par exemple sur la première ligne : =LOI.NORMALE.INVERSE(H2;0;1).
- Recopiez cette formule vers le bas pour toutes les lignes suivantes.
- Sélectionnez à la souris toute la plage (F2:F21) des résidus observés, puis (en maintenant la touche CTRL enfoncée pour ne pas déselectionner la plage précédente) toute la plage des résidus théoriques (I2:I21).
- Cliquez sur le bouton de graphique de votre tableur, pour créer un graphique XY (dispersion, ou nuage de points). Si la distribution des résidus est suffisamment proche de la normale, on devrait avoir une relation linéaire entre résidus observés et théoriques (points proches de la droite Y=X).
- Pour quantifier cette relation linéaire, calculez dans une case en bas de tableau la corrélation linéaire entre les deux séries de valeurs : =COEFFICIENT.CORRELATION(F2:F21;I2:I21). On trouve une valeur très élevée de $R=0.9946$.
- Le coefficient $W$ de Shapiro-Wilk est par définition le carré de cette valeur : $W=R^2=0.9892$. Il varie par construction entre 0 et 1, une valeur proche de 1 illustrant une bonne proximité à la loi normale.
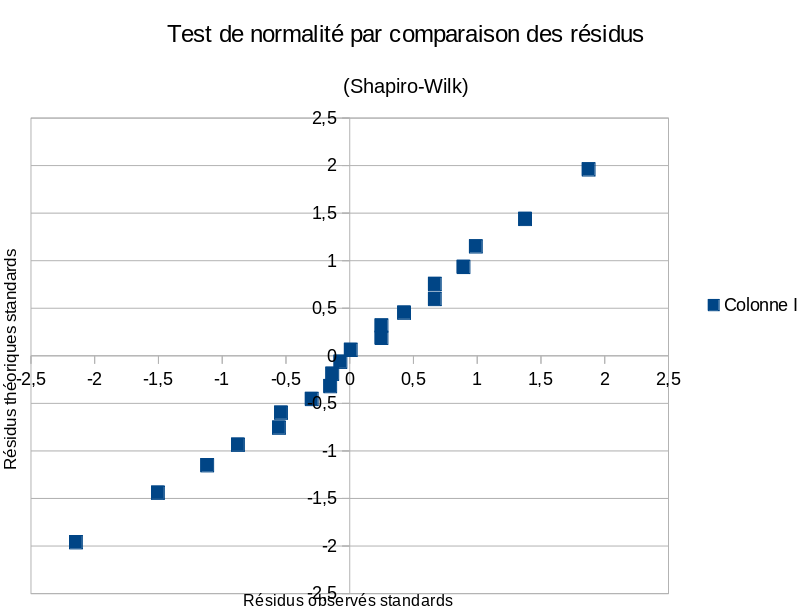
- Calculez dans la colonne J les probabilités cumulées de la loi normale standard associées au résidus observés qui sont en colonne F. Par exemple sur la première ligne (pour LibreOffice): =LOI.NORMALE.STANDARD(F2;1) (ou =LOI.NORMALE.STANDARD.N(F2;1) sous EXCEL).
- Recopiez cette formule vers le bas pour toutes les lignes suivantes.
- Sélectionnez à la souris (en maintenant la touche CTRL enfoncée) les trois plages de : résidus standardisés (F2:F21), fréquences cumulées observées (H2:H21) et probabilités théoriques normales (J2:J21). Créez un nouveau graphique de dispersion XY, en choisissant un affichage de type ligne cette fois-ci.
- On définit la statistique dite $D_{max}$ de Kolmogorov comme le plus grand écart absolu existant entre la série des fréquences cumulées observées et la série des probabilités cumulées théoriques. Dans une dernière colonne K, calculez les différences, en valeur absolue, entre les deux colonnes H et J correspondantes. Par exemple sur la première ligne : =ABS(H2-J2).
- En bas de cette colonne des différences, calculez son maximum : =MAX(K2:K21). On trouve une valeur assez faible de $D_{max}=0.0644$.
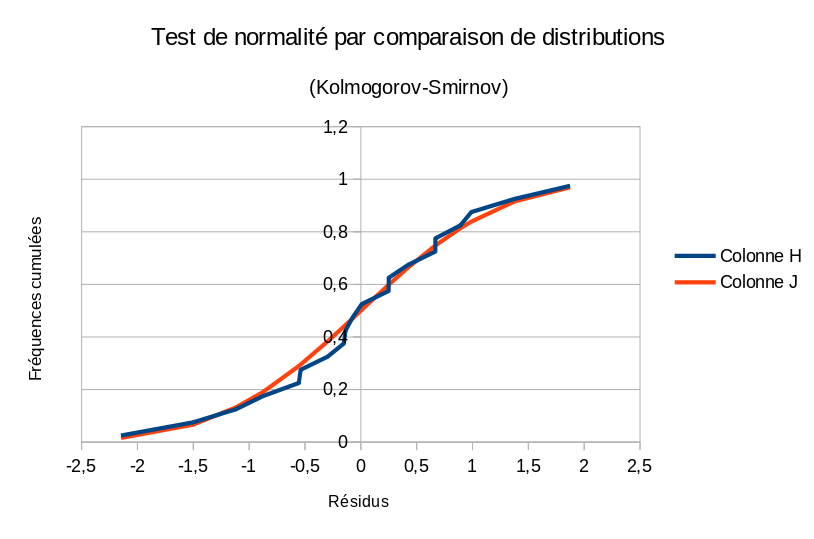
-
expand_moreEn résumé
Le fichier final corrigé de l'exercice précédent peut être téléchargé au format OpenOffice ou EXCEL. On note que :
- R2STATS fournit par défaut un test de normalité de Shapiro-Wilk, qui est un des tests de détection de déviation à la loi normale les plus puissants. Dans l'onglet Résultats, on trouve $W= 0.99121, p < 0.9992$.
- La valeur du $W$ n'est pas identique à celle que nous avons calculée à la main car le test utilise une manière un peu plus sophistiquée de calculer les résidus théoriques (statistiques d'ordre). Mais le principe d'une corrélation au carré, au coeur du test, est bien illustré dans l'atelier.
- Pour l'inteprétation, on se base sur la valeur $p$ : plus elle est élevée, moins on a de raisons de rejeter l'hypothèse de normalité, qui représente l'hypothèse nulle du test. Les principes de cette interprétation sont détaillés dans la section suivante.
Seuil de décision et erreur de type II
Tout comme le test d'homogénéité des variances, le test de normalité fait partie de la famille des test d'ajustement. Par contraste avec les usages plus fréquents des tests à valeur $p$ qui visent à mettre en évidence des différences ou effets suprenants, au regard d'un certain modèle attendu de distribution, les tests d'ajustement cherchent au contraire à argumenter l'absence de différence, ou une différence négligeable (entre deux variances, ou entre une distribution et la loi normale par exemple).
Les tests à valeur $p$ ne sont pas très appropriés pour ce type d'objectif car ils sont intégralement conçus pour poser d'abord une hypothèse d'absence d'effet (l'hypothèse nulle), et éventuellement se trouver surpris par un résultat que cette hypothèse ne permet pas raisonnablement d'attendre. Lorsque cette hypothèse de départ est précisément ce que vous voudriez valider, la méthode est un peu prise en défaut, car ne pas rencontrer de contradiction (i.e. une valeur $p$ élevée) n'est pas synonyme de confirmation. Pour cette raison, les tests à valeur $p$ ne permettent de connaître la probabilité de se tromper que quand on cherche le rejet de l'hypothèse nulle (c'est ce qu'on appelle l'erreur de type I). Quand on souhaite se rassurer au contraire sur sa plausibilité, tout ce qu'on peut faire est d'espérer une valeur $p$ aussi élevée que possible.
Dans ce sens là, l'erreur que l'on cherche à contrôler est l'erreur qui consisterait à affirmer l'hypothèse nulle alors qu'elle est fausse (c'est l'erreur de type II). En se donnant un seuil de décision plus élevé que d'habitude (par exemple $\alpha=0.10$, par pure convention pédagogique), et en ne rejetant pas l'hypothèse nulle quand la valeur $p$ observée est supérieure à ce seuil élevé, on minimise cette erreur (sans pouvoir réellement la quantifier). C'est la règle que nous adopterons autant pour le test d'homogénéité des variances que pour le test de normalité.
Dans l'analyse des données de Fox & Guyer (1978), nous avons trouvé $W = 0.99121, p < 0.9992$ pour la normalité, et $F = 0.40265, p < 0.1916$ pour l'homogénéité des variances. Les deux valeurs $p$ sont supérieures au seuil $\alpha=0.10$ et nous ne rejetons pas la normalité et l'homogénéité. Le modèle de groupe gaussien est donc acceptable et nous pouvons procéder au calcul et à l'interprétation d'un test sur les moyennes ($T$ de Student).